El 28 de Octubre volvimos con Cambá a la Nodeconf 2017. Las puertas abrieron unos minutos más tarde de los normal, fuimos a buscar los exquisitos desayunos frutales y nos apresuramos a encontrar buenas ubicaciones.
La primer charla del día estuvo a cargo de Michelle Garret. El temario abarcó los node_modules, su administración, priorización a la hora de elegir un módulo y el impacto que tienen sobre nuestros proyectos. ¿Qué criterios deberíamos tener a la hora de elegir? Es ideal tener una visión clara del mantenimiento y el estado del módulo en cuestion. Es preferible incluir un software que tenga una API intuitiva, tests, documentación actualizada, mantenimiento constante y activo. No menos importante es la cantidad de usuarios que están contribuyendo o que simplemente utilizan la herramienta.
 Poniendo a prueba éstos criterios contó su experiencia sobre ciertos frameworks que resolvían el mismo propósito, con diferentes implementaciones y modos de uso. (Imagemagick vs GraphicsMagick). ImagesMagick es un módulo relativamente liviano que nos proporciona una API bastante intuitiva para aplicar elementos gráficos, destellos, filtros, etc, sobre una imágen. GraphicsMagick nos trae la misma solución, con la diferencia que es un poquito mas pesado. Normalmente siempre pensamos en el tamaño resultante de nuestra app y elegiríamos el módulo mas liviano disponible. En éste caso Michell nos propone abstraernos un poco más allá del tamaño original del módulo y entender las consecuencias finales para entender por qué, en éste ejemplo, ella elige la librería de GraphicsMagick.
Poniendo a prueba éstos criterios contó su experiencia sobre ciertos frameworks que resolvían el mismo propósito, con diferentes implementaciones y modos de uso. (Imagemagick vs GraphicsMagick). ImagesMagick es un módulo relativamente liviano que nos proporciona una API bastante intuitiva para aplicar elementos gráficos, destellos, filtros, etc, sobre una imágen. GraphicsMagick nos trae la misma solución, con la diferencia que es un poquito mas pesado. Normalmente siempre pensamos en el tamaño resultante de nuestra app y elegiríamos el módulo mas liviano disponible. En éste caso Michell nos propone abstraernos un poco más allá del tamaño original del módulo y entender las consecuencias finales para entender por qué, en éste ejemplo, ella elige la librería de GraphicsMagick.
Resulta que si bien ImageMagick nos facilita la vida para agregar un filtro en unas pocas líneas de código, tiene dependencias en C++. Localmente no representa ningún problema, podemos hacer pruebas y deploys sin tanto trabajo Pero si necesitamos realizar una integración contínua para hacer un deploy remoto vamos a tener que instalar éstas subdependencias manualmente.
Por alguna razón Michelle nos dejó como bonus ésta divertida app que genera nombres de Node Drag Queens aleatorios utilizando comentarios en twitter: https://jsdrag.now.sh/
Daniel Khan hosteó la segunda charla. Nos contó que necesitaba implementar un software para exponer métricas de performance sobre el uso de un software escrito en Javascript. Esta tarea lo llevó a investigar el Event Loop de Node y, para su sorpresa, la mayoría del material explicativo que encontró estaba muy fuera del panorama real. Decidido a desmitificar los conceptos internos del Event Loop expuso lo aprendido durante su investigación.
Event Loop: ¿qué no es?
En Javascript no hay una pool de threads para manejar eventos. El Event Loop tampoco es una cola de funciones.
¿Qué es Javascript?
Un lenguaje basado en eventos en un solo thread, asincrónico en el i/o y utiliza el módulo libuv para ejecutar, mantener y gestionar los eventos. En pocas palabras, Libuv crea por default cuatro threads que se utilizan cuando no se hacen llamados a una API asincrónica.
Event Loop: ¿qué es?
No es más que un grupo de fases con estructuras de datos que son ejecutadas mediante ticks, que permiten que Node pueda realizar operaciones de i/o de manera asincrónica. Cada fase consta de una cola FIFO con callbacks a ejecutar. El Event Loop ejecuta todos los callbacks que puede de la fase actual antes de pasar a la siguiente, puede llegar a un límite o puede que la cola se vacíe completamente.
 En resumen, las fases son las siguientes:
En resumen, las fases son las siguientes:
Timers: por ejemplo, llamados a setTimeOut
Callbacks de I/O: ejecuta casi todos los callbacks, excepto aquellos encolados en Timers, llamados a setInmediate y eventos de close.
Poll: recupera nuevos eventos de I/O
Check: ejecuta todos los callbacks de setInmediate
Close Events: se ejecutan todos los eventos de close.
- Link de interés:
Otra de las charlas de mayor valor fue presentada por Athan Reines. Este muchacho se dedica a realizar análisis y estadísticas sobre grandes cantidades de datos, por lo que es necesario poder manejar bastantes cantidades de computos. En Node tenemos la posibilidad de utilizar addons  para realizar computos con otras librerías que posiblemente estén mejor preparadas para operaciones que no deberíamos ejecutar directamente en el browser.
para realizar computos con otras librerías que posiblemente estén mejor preparadas para operaciones que no deberíamos ejecutar directamente en el browser.
Athan nos explica como integrar addons en javascript, particularmente para librerías de C y FORTRAN. Un addon provee una interfaz entre una librería cualquiera y el ambiente de Node, en este caso.
Utilizando gyp de node, se puede declarar en un archivo de configuración el lenguaje de la librería a utilizar, el target o versión del lenguaje y las funciones o sources que ésta exporta (si es C, nuestra configuración apuntaría a los archivos .h).
Nodegyp se encarga de compilar los archivos especificados en la configuración y dejarnos el ambiente listo con las funciones externas a node que decidimos exponer.
Su estudio sobre addons de C y FORTRAN para realizar operaciones sobre listas dio como resultado que para arrays entre 10 y 1.000 elementos sigue siendo conveniente utilizar javascript nativo, entre 1.000 y 10.000 elementos es conveniente optar por webassembly y, para operaciones de mas de 10.000 deberíamos optar por addons.
Según Athan, FORTRAN resultó útil con un número de operaciones superiores a 100.000 en algunos casos. La dificultad de integrar una librería de FORTRAN reside en la configuración, ya que además de especificar los directorios y target para que gyp pueda interpretar los sources de C, debemos añadir instrucciones sobre como C debe consumir la librería de FORTRAN.
Link al repositorio de la charla:
Claudia Hernández es una desarrolladora mexicana que vino desde Francia para ofrecernos una explicación sobre sorting.
¿Por qué Javascript no ordena elementos como imaginamos?
A partir de una lista con los números [4, 3, 2, 5, 33, 21] esperaríamos obtener como resultado [2, 3, 4, 5, 21, 33]. ¡Pero no! No es asi… en cambio estaríamos obteniendo [2, 21, 3, 33, 4, 5].
Javascript utiliza su función .sort, que ordena elementos lexicográficaficamente por default. Esto significa que Javascript no compara números, sino strings caracter por caracter hasta que uno de ellos es diferente.
Existen soluciones a éste tipo de problemáticas (si es que quisiéramos considerarla como tal…)
Una de ellas es implementar nuestra propia función de sorting que ordene los elementos de otra manera.
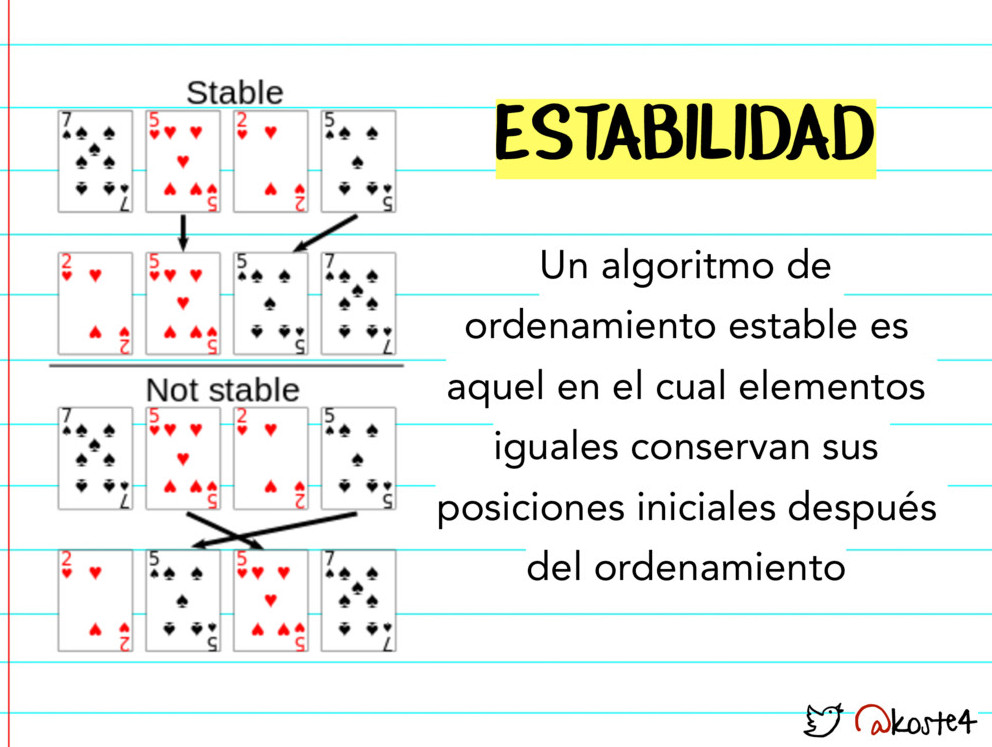 Pero las funciones de sorting no se dividen únicamente entre lexicográficas o no, los algoritmos pueden ser estables o no. Un algoritmo estable es aquel que recuerda que el número 2 se encontraba primero que el 22, entonces el ordenamiento daría como resultado que el 2 se encuentre antes del 22. Algunos browser implementan algoritmos no estables, es decir que no pueden asegurar que el 2 vaya a posicionarse antes del 22 cuando se ordene la lista.
Pero las funciones de sorting no se dividen únicamente entre lexicográficas o no, los algoritmos pueden ser estables o no. Un algoritmo estable es aquel que recuerda que el número 2 se encontraba primero que el 22, entonces el ordenamiento daría como resultado que el 2 se encuentre antes del 22. Algunos browser implementan algoritmos no estables, es decir que no pueden asegurar que el 2 vaya a posicionarse antes del 22 cuando se ordene la lista.
Para finalizar, Claudia nos mostró qué algoritmos implementan distintas plataformas junto con una breve explicación de Insertion, Merge y Quick sort. Sus implementaciones en Javascript las pueden encontrar en el link de las diapositivas.
Para arrays pequeños Chrome y Firefox utilizan ambos Insertion Sort, mientras que para arrays de mayor tamaño Chrome implementó un Quick Sort y Firefox un Merge Sort.
Link de la charla + diapositivas:
A mi parecer, la demo mas atractiva la llevaron a cabo Nikhila Ravi y Anshul Bhagi. Desarrollaron un plugin para browsers que permite identificar en palabras objetos representados en una imágen cualquiera.
Los chicos nos dieron una breve explicación sobre Machine learning e inteligencia artificial. Nosotros, los humanos aprendemos mediante Pull Learning. Nos enriquecemos de lo que percibimos, lo aprendemos y lo adoptamos. En cambio, las máquinas aprenden a distinguir lo que es, de lo que no es. Mediante una comunicación entre capas, un sistema basado en machine learning descarta y aprueba cientos de miles de posibilidades basándose en patrones que podrían o no coincidir con, en éste caso, un grupo de píxeles que representan una fotografía.
En ésta aplicación existen tres fases importantes. La primera consta de una Input Layer que recibe una imágen. La segunda consta de un modelo de la imágen que se encarga de agrupar sectores significativos (características, dimensiones, curvas, colores) de la imágen comparándolos con parámetros predefinidos entre una gran cantidad de Hidden Layers. Finalmente existe un modelo de texto donde a partir de las opciones que no fueron descartadas por las Hidden Layers se generan oraciones de palabras que en definitiva intentan describir qué hay o qué está sucediendo en la imagen.
Más información sobre el proyecto:
La última charla fue presentada por Kat Marchán de npm. Nos vino a contar las features que vinieron en la quinta versión de la cli de npm que se supone es un 647% más rápida que la versión 4.
Entre otras características, se añade soporte para los hash de integridad en SHA-512, permite instalar paquetes en modo offline o ejecutarlos sin descargar, con el comando npx y se adoptó p or default el flag – -save. Otra novedad es la creación automática de un nuevo archivo para la configuración de dependencias: package-lock.json. Es un archivo que tiene una finalidad muy parecida al ya conocido package.json, con la diferencia que garantiza que tanto otros integrantes de un mismo equipo de trabajo o durante integraciones contínuas o deploys se utilice el mismo árbol de dependencias durante la instalación del entorno. Cada vez que se actualiza el pacakge.json o se instalan dependencias directamente en node_modules el package-lock.json se actualiza para mantener el mismo árbol de dependencias que se están utilizando actualmente.
or default el flag – -save. Otra novedad es la creación automática de un nuevo archivo para la configuración de dependencias: package-lock.json. Es un archivo que tiene una finalidad muy parecida al ya conocido package.json, con la diferencia que garantiza que tanto otros integrantes de un mismo equipo de trabajo o durante integraciones contínuas o deploys se utilice el mismo árbol de dependencias durante la instalación del entorno. Cada vez que se actualiza el pacakge.json o se instalan dependencias directamente en node_modules el package-lock.json se actualiza para mantener el mismo árbol de dependencias que se están utilizando actualmente.
Links al blog y releases notes: